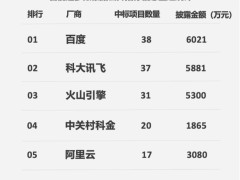
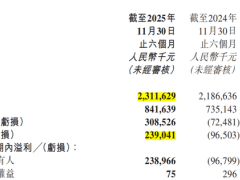
在人工智能大模型競爭日益激烈的當下,如何打造一款能精準“抓住”用戶的爆款應用,成為眾多開發(fā)者關注的焦點。當算力與性能不再是唯一優(yōu)勢,個性化技術(shù)成為關鍵突破口。傳統(tǒng)推薦系統(tǒng)和對話模型依賴ID Embedding或特定參數(shù)表示用戶偏好,這種“黑盒”范式存在不可解釋、難以遷移等問題,限制了個性化發(fā)展。而大模型強大的推理與生成能力,為打破這一局限帶來新契機,推動個性化從“黑盒”走向“白盒”。
近日,一支由螞蟻與東北大學研究人員組成的團隊,在大模型個性化領域取得重要進展,推出AlignXplore+。該成果實現(xiàn)文本化用戶建模新范式,讓復雜用戶偏好既能被人理解,也能被機器解讀,還具備良好擴展性與遷移性。傳統(tǒng)個性化技術(shù)路線下,無論是靜態(tài)用戶向量還是為每個用戶微調(diào)模型,本質(zhì)都是不透明的“黑盒”。團隊指出,這種表示方式存在兩大痛點:一是不可解釋性,用戶無法理解、修改系統(tǒng)定義的“自己”,在注重隱私與控制權(quán)的AI Agent時代難以接受;二是無法遷移,向量和參數(shù)與特定模型架構(gòu)深度綁定,推薦系統(tǒng)里的興趣無法被聊天機器人復用,不同模型間的畫像也難以通用。
基于這些思考,團隊提出范式轉(zhuǎn)移:摒棄隱空間向量,直接用自然語言歸納和推理解析用戶偏好。這種基于文本的偏好歸納,人眼可讀、可控,且完全解耦偏好推理與下游模型和任務。無論是推薦、寫作還是閑聊,也無論是GPT、Llama還是Qwen,都能無縫“讀懂”用戶。
AlignXplore+具有三大核心特性,重構(gòu)用戶理解范式。其一,全域通用,打破數(shù)據(jù)孤島。它不局限于單一交互形式,可處理真實世界中異構(gòu)數(shù)據(jù)源,如社交網(wǎng)絡發(fā)帖、電商平臺點擊、新聞流瀏覽記錄等,能提煉高價值偏好摘要,拼湊完整用戶全貌。其二,極致遷移,一次畫像,處處通用。從單一任務到全能應用,它打破任務邊界,將能力擴展到推薦和生成等廣泛個性化應用;從特定模型到通用接口,實現(xiàn)跨模型遷移,生成的畫像可被任何下游大模型直接讀取使用。其三,實戰(zhàn)適配,無懼真實世界數(shù)據(jù)噪點。真實世界交互流式且充滿噪點,AlignXplore+無需每次都重新“閱讀”用戶所有歷史,像人類記憶一樣,基于舊摘要和新交互不斷演化;面對“不完美信號”,如缺乏明確負反饋的數(shù)據(jù)和跨平臺混合數(shù)據(jù),仍能保持穩(wěn)定推理能力,免受噪音干擾。
AlignXplore+是一個面向大模型個性化對齊的統(tǒng)一框架,核心目標是讓大模型在不重訓、不續(xù)訓前提下持續(xù)理解用戶。該框架包含兩個主要階段。SFT階段通過“生成 - 驗證 - 合并”流程創(chuàng)建高質(zhì)量訓練數(shù)據(jù),確保對多個未來交互的準確預測,綜合生成全面偏好總結(jié)。RL階段采用課程剪枝策略,選取推理密集型樣本,并通過累積獎勵函數(shù)優(yōu)化偏好總結(jié),提升流式場景中的長期有效性。
在這個框架下,團隊將“用戶偏好學習”拆解為兩個核心步驟。SFT階段,為解決文本化偏好歸納“太泛”或“太偏”問題,設計一套流程,讓模型基于多種可能未來交互行為反推當前偏好,并引入“行為驗證”機制,確保生成的用戶偏好能準確預測用戶行為。RL階段,僅有SFT不夠,團隊引入強化學習,設計課程剪枝和累積獎勵兩個關鍵機制。課程剪枝篩選出“難但可解”的高推理價值樣本,避免模型在簡單或不可解樣本上空轉(zhuǎn);累積獎勵讓模型關注生成的用戶偏好在未來持續(xù)交互中的可演化性,適應流式更新。
相較于現(xiàn)有方法,AlignXplore+在用戶理解準確性、遷移能力和魯棒性上實現(xiàn)全面升級。在效果上,8B參數(shù)的AlignXplore+在包含推薦、回復選擇和回復生成的九大基準測試中,平均分數(shù)取得SOTA成績,平均得分75.10%,絕對提升幅度比GPT - OSS - 20B高出4.2%,在復雜任務上表現(xiàn)尤為突出,驗證顯式推理比隱式向量更能捕捉深層意圖。在遷移能力上,生成的用戶偏好展現(xiàn)驚人Zero - shot遷移能力。跨任務遷移方面,對話任務中生成的偏好,直接指導新聞推薦依然有效;跨模型遷移方面,生成偏好給Qwen2.5 - 7B或GPT - OSS - 20B等不同下游模型使用,均能帶來穩(wěn)定性能提升,用戶偏好不再被單一模型鎖定。在魯棒性上,真實場景往往只有用戶點擊記錄(正樣本),缺乏明確負反饋,實驗表明,即便移除所有負樣本,AlignXplore+依然保持顯著性能優(yōu)勢,展現(xiàn)強大推理魯棒性。用戶真實歷史行為跨越多種領域,實驗結(jié)果顯示,即使混合不同領域歷史記錄,AlignXplore+依然能精準捕捉多重興趣,不像傳統(tǒng)模型那樣將興趣“平均化”。