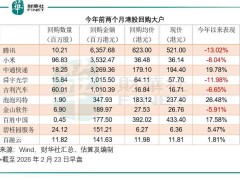
在人工智能領(lǐng)域,一場引人矚目的變化正在悄然發(fā)生。最新數(shù)據(jù)顯示,2月9日至2月15日期間,中國人工智能大模型的調(diào)用量達到4.12萬億Token,首次超越同期美國模型的2.94萬億Token。這一數(shù)據(jù)不僅標志著中國在AI大模型應用上的重大突破,也反映出全球人工智能格局的深刻演變。
Token,作為AI理解人類語言的基本單元,其作用類似于嬰兒學習語言時被拆解的字詞。在AI系統(tǒng)中,無論是中文還是英文,文本都會被分解為Token進行處理。例如,中文句子“今天天氣很好。”會被拆分為“今”“天”“天”“氣”“很”“好”“。”等約7個Token。這種處理方式使得AI能夠逐步理解并生成符合人類語言習慣的文本。
AI大模型的運行機制可以類比為廚師烹飪的過程:用戶的提問是食材,模型的回答是菜品,而Token則是運輸食材和菜品的“盤子”。當前的大模型對單次處理的文字量有嚴格限制,輸入和輸出的總Token數(shù)不能超過一定閾值。部分AI工具甚至根據(jù)Token使用量收費,輸入輸出文字越多,費用越高。因此,Token調(diào)用量不僅是技術(shù)指標,更是衡量AI大模型實際應用價值的重要標尺。
中國大模型調(diào)用量的領(lǐng)先并非偶然。數(shù)據(jù)顯示,2月16日至2月22日,中國大模型調(diào)用量進一步攀升至5.16萬億Token,而美國同期僅為2.7萬億Token。這一趨勢背后,是中國超大規(guī)模市場和豐富應用場景的雙重驅(qū)動。截至2025年6月,中國生成式人工智能用戶規(guī)模已達5.15億人,較2024年12月激增2.66億人。用戶基數(shù)的擴大推動AI從互聯(lián)網(wǎng)領(lǐng)域向辦公、工業(yè)設(shè)計等深層場景滲透,使其從“技術(shù)嘗鮮”轉(zhuǎn)變?yōu)椤叭粘9ぞ摺薄M瑫r,應用滲透率的提升也為模型迭代提供了海量數(shù)據(jù)反饋,顯著增強了其處理復雜任務的能力。
技術(shù)生態(tài)的完善同樣功不可沒。從算力基礎(chǔ)設(shè)施到開源社區(qū),從高校科研到企業(yè)創(chuàng)新,中國已形成協(xié)同發(fā)展的創(chuàng)新體系。目前,中國人工智能企業(yè)數(shù)量超過6000家,2025年核心產(chǎn)業(yè)規(guī)模預計突破1.2萬億元。廠商通過降低調(diào)用成本擴大用戶群體,進一步激活了創(chuàng)新生態(tài)。這種“技術(shù)-市場”的良性循環(huán),為中國AI大模型的持續(xù)進化提供了強大動力。
這場變革不僅體現(xiàn)在數(shù)據(jù)層面,更深刻改變了全球人工智能的競爭格局。中國大模型的崛起,標志著AI技術(shù)正從實驗室走向千行百業(yè),從少數(shù)國家的專屬工具轉(zhuǎn)變?yōu)槿蚬蚕淼幕A(chǔ)設(shè)施。隨著應用場景的不斷拓展和技術(shù)突破的持續(xù)加速,中國人工智能正在為全球創(chuàng)新貢獻獨特方案。