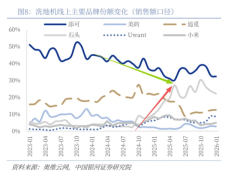
近日,一份由數巔科技發布的205頁技術報告引發行業關注,該文檔以系統化視角梳理了大語言模型從理論到落地的全鏈路技術體系,為數據智能的規模化應用提供了可復用的方法論。報告通過理論解析、技術拆解與案例實踐三重維度,揭示了大模型如何重構傳統AI開發范式,并推動智能技術向更普惠的方向發展。
在技術演進脈絡中,報告指出大模型的核心突破源于參數規模的指數級增長與訓練方法的迭代創新。從早期基于統計學的語言模型,到Transformer架構打破序列處理瓶頸,再到GPT-3通過千億級參數驗證涌現能力,技術路徑清晰呈現"量變引發質變"的特征。國內科研力量在此領域表現突出,文心一言、ChatGLM等模型不僅在參數規模上比肩國際水平,更在中文語境理解、多模態交互等維度形成差異化優勢。這些模型展現的少樣本學習能力、上下文關聯推理能力,正在重塑人機協作的邊界。
構建高效訓練體系是報告重點剖析的技術模塊。針對大模型訓練面臨的算力瓶頸,文檔詳細拆解了分布式訓練策略:數據并行通過切分訓練樣本提升吞吐量,模型并行則將神經網絡層分配至不同計算節點,二者結合可支撐萬億參數模型的訓練需求。為解決內存墻問題,混合精度訓練、ZeRO優化等技術通過壓縮存儲占用與通信開銷,使訓練效率提升3-5倍。在架構層面,參數服務器與去中心化通信模式的對比分析,為不同規模團隊提供了可適配的解決方案。
應用開發環節的革新同樣值得關注。報告提出"Prompt工程替代子模型訓練"的新范式,通過設計精準的指令模板,開發者可快速激活大模型的特定能力,這種敏捷開發模式使項目周期縮短60%以上。LangChain框架的組件化設計進一步降低開發門檻,其內置的記憶管理、工具調用等模塊,支持快速構建智能問答、數據分析等應用。在效率優化方面,KV緩存技術通過復用中間計算結果減少推理延遲,vLLM框架則通過動態批處理提升GPU利用率,實測顯示模型響應速度提升2-4倍。
為確保技術可靠落地,報告構建了多維評估體系。從知識完備性、倫理安全性到復雜推理能力,12項核心指標形成立體化評估矩陣。自動評估工具與人工審核的協同機制,既保證評估效率又控制質量風險。針對不同應用場景,分類任務采用F1值、回歸任務使用MAE指標、生成任務則通過BLEU評分進行量化評估。MMLU、C-eval等權威基準測試的引入,為模型能力提供客觀參照標準。
實踐案例部分,個人知識庫問答助手的開發流程具有典型示范意義。從需求分析階段的場景定義,到數據清洗時的隱私保護處理,再到Prompt設計遵循的"清晰性、完整性、適應性"原則,每個環節都提供可操作的執行清單。部署環節對比了云服務與邊緣計算的適配場景,指出模型輕量化與硬件加速的協同優化方向。這種端到端的案例解析,為傳統企業數字化轉型提供了可直接復用的技術路線圖。